Guiding Quote
"I am not designed to come second or third. I am designed to win."
ZDisket Portfolio
Specializing in Speech Synthesis, Transformers, and C++ software dev.
"I am not designed to come second or third. I am designed to win."
Buenos Aires, Argentina
Core systems engineering, ML research, and acceleration tooling.
Structured in multi-year arcs, ordered newest to oldest. Each entry is either a project case study, a research case study, or a milestone that marks a career-shaping shift.
Neo-Hybrid Arc
2026-present
Research, product, and business reinforce each other in a single operating loop.
Waveform-domain enhancement model built to repair neural codec artifacts while upsampling degraded 24 kHz speech to 48 kHz output. It follows a synthesis-first design to rebuild detail instead of preserving artifact patterns.
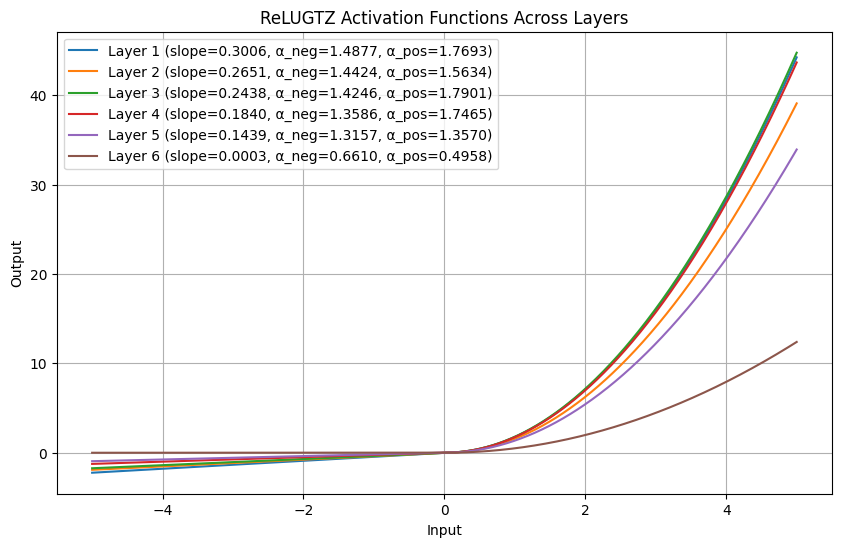
Optimized evolution of the VITS text-to-speech architecture focused on extreme real-time performance with practical audio quality. Current builds reach about 300x real-time on an NVIDIA A6000 and run in TensorVox through ONNX + DirectML on Windows 10+ DX12 GPUs.
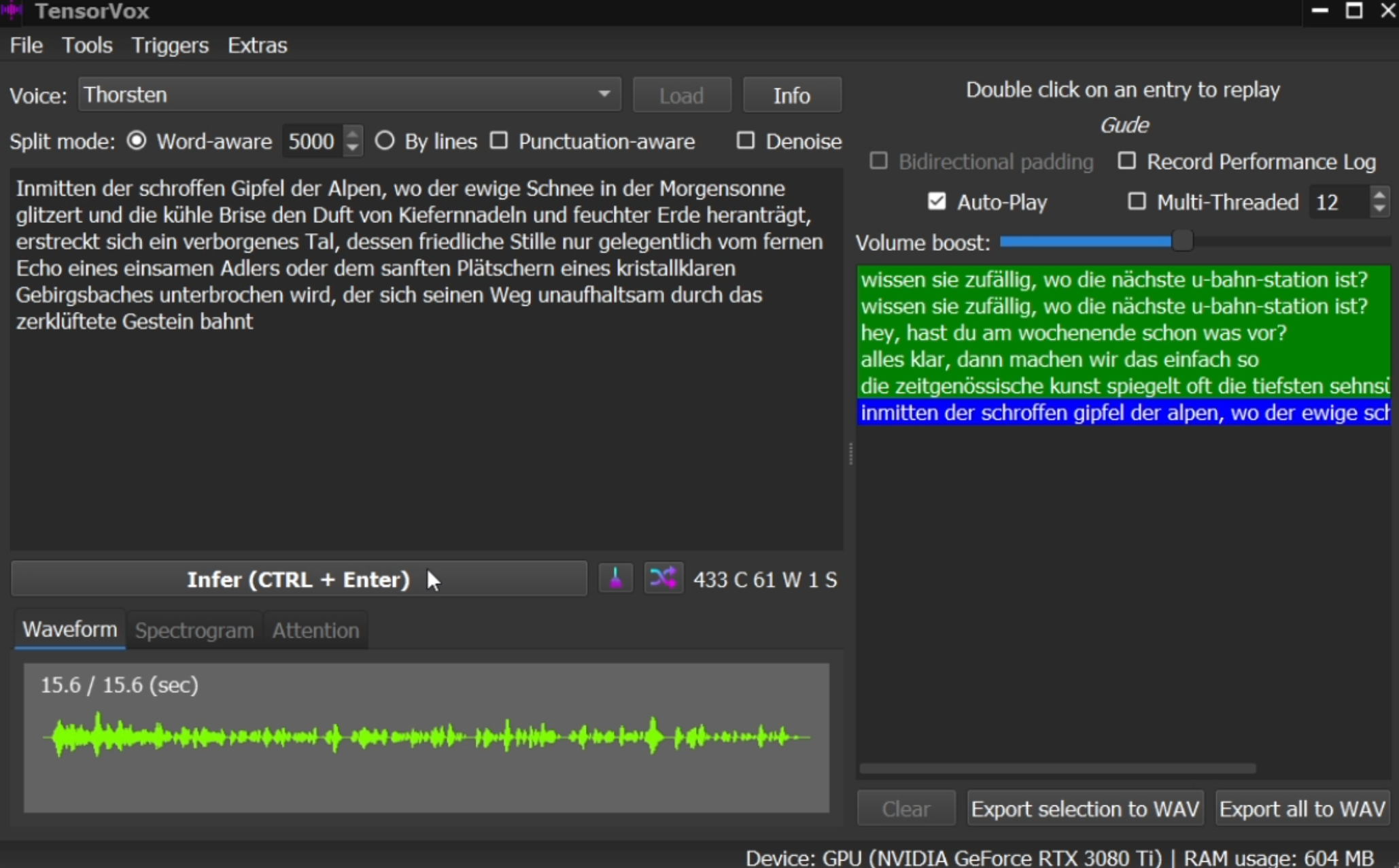
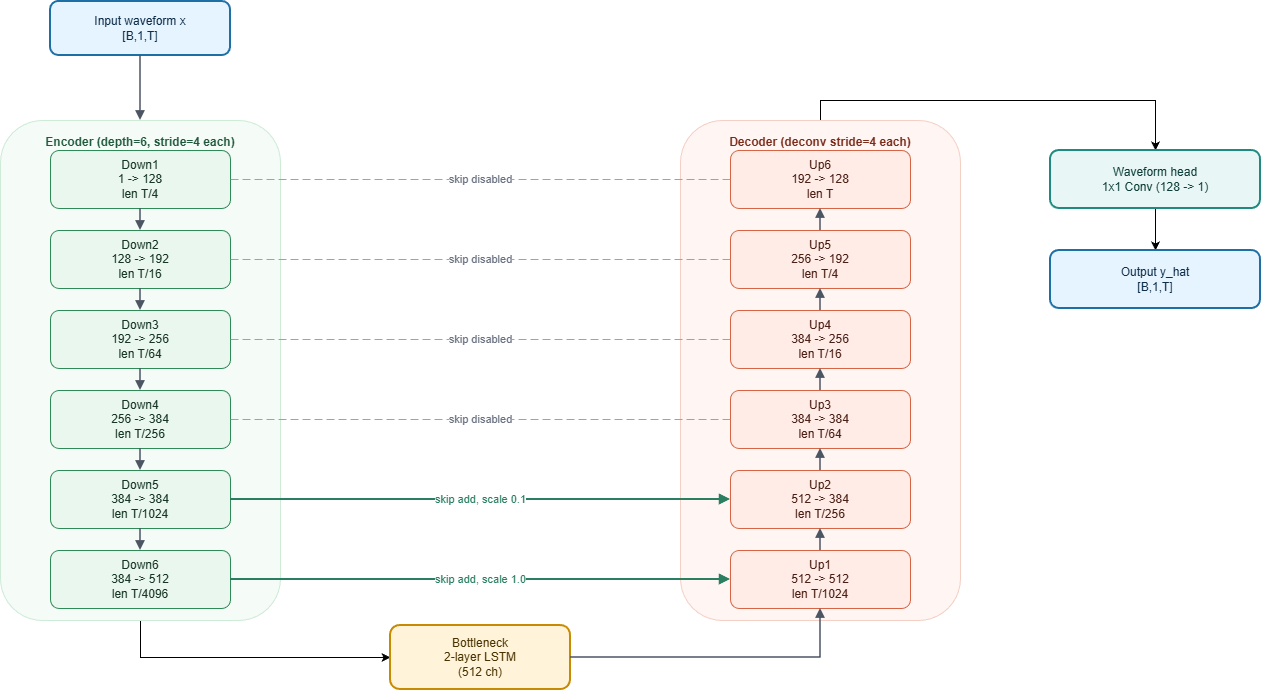
Integrated VITS EVO into TensorVox with ONNX + DirectML, proving native Windows 10+ GPU inference across DX12 hardware and demonstrating a clear path from model research to user-facing delivery.
Pure Research Arc
2023-2025
Deep neural audio exploration with frequent experimental iteration and publication.
Text-to-speech model trained on concatenated text-audio tokens using a decoder-only LLM-style architecture. Uses a 50 tok/s codebook for efficient audio language modeling with high-fidelity output.
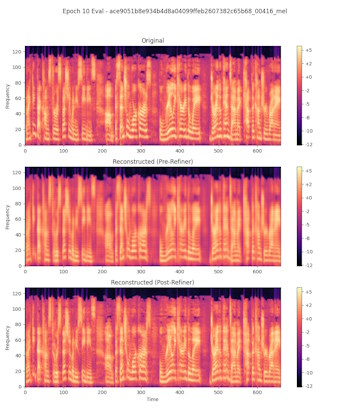
Experimental audio tokenization built around a spectrogram codec, with a ResNet compressor and U-Net refiner for cleaner reconstruction. Designed to keep tokenized workflows compact while improving output quality.
Earned ROCm Star recognition through hands-on work with AMD acceleration hardware and tooling in real model training contexts.
Lightweight C++/Qt frontend for Stable Diffusion with no Python dependency for end users. Supports txt2img, img2img, and inpainting in a native Windows workflow.
Joined a startup context and shifted into deeper architecture and training-detail work, tightening the loop between research decisions and shipped outcomes.
Hybrid Arc
2020-2023
Software engineering and ML research overlapped to produce practical model tooling.
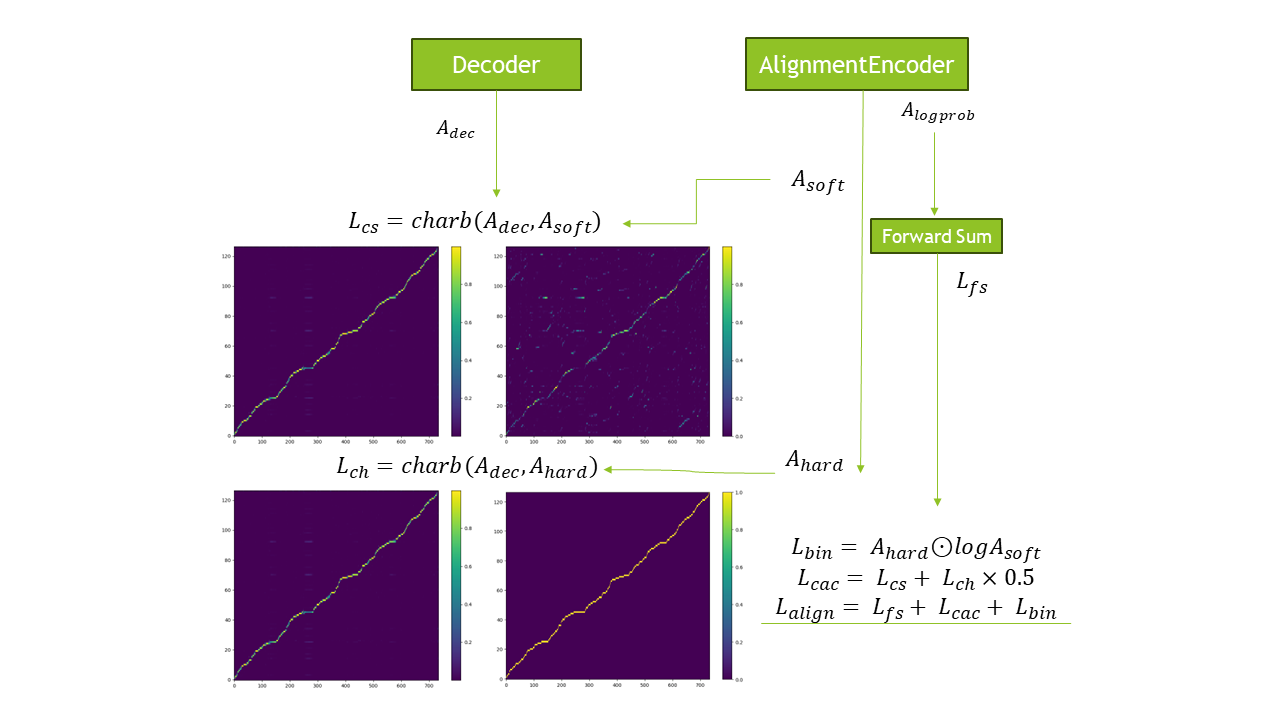
Convolutional Attention Consistency approach for stabilizing Tacotron 2 attention. Built to reduce alignment failures and improve training reliability.
High-performance local TTS application written in C++/Qt with support for both PyTorch and TensorFlow models. Widely used for freelancing deliverables and model deployment workflows.
Contributed the first 44.1KHz open-source pretrained model in the repository, expanding practical high-fidelity speech options for the community.
Implemented C++ export and runtime usage through the TensorFlow SavedModel C API, broadening deployment options beyond Python-only workflows.
WinDev Arc
2015-2020
Early system-builder years focused on complete desktop tools and shipping discipline.
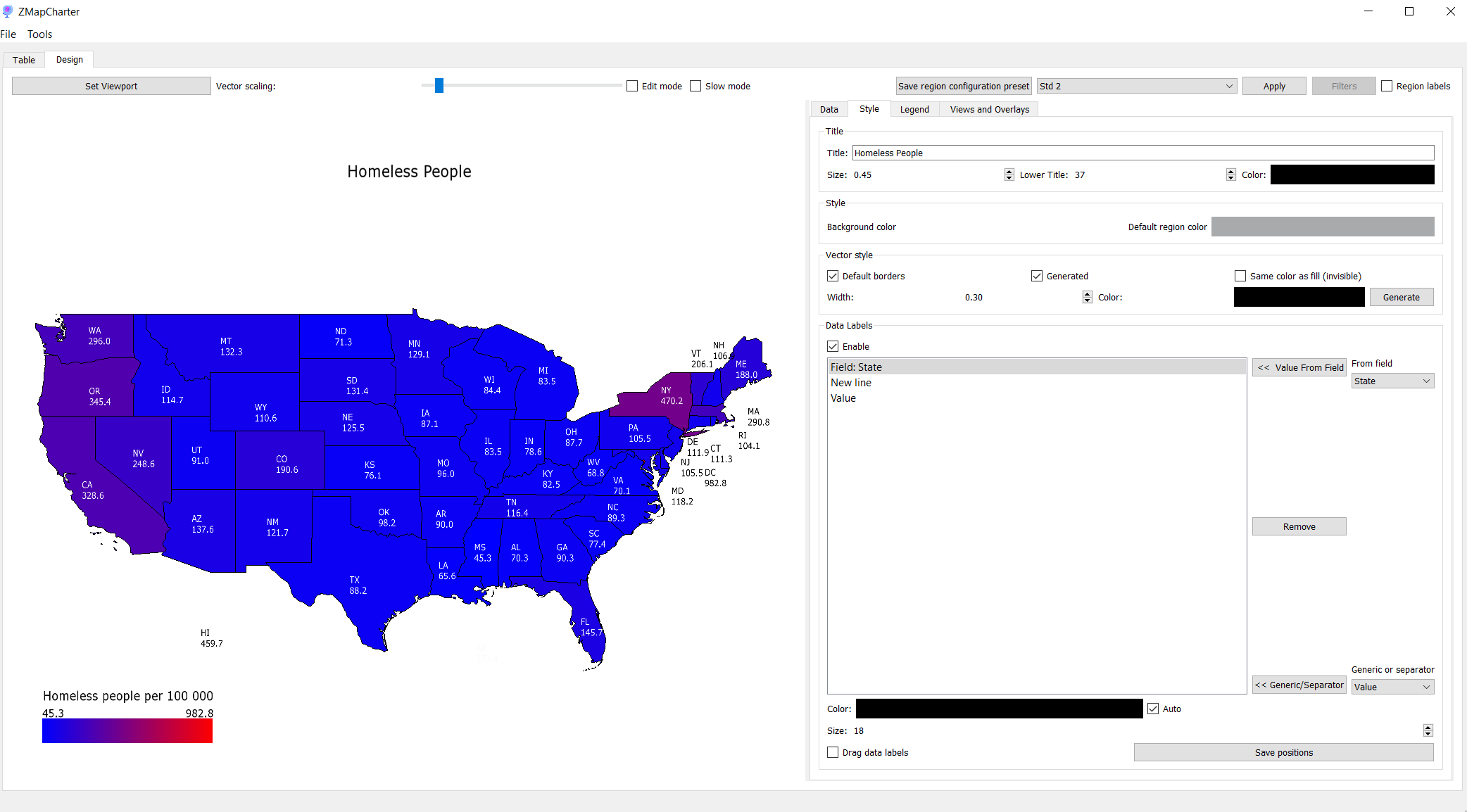
Statistical map charting tool built with C++ and SFML. Supports custom shapefiles and CSV/XLSX imports for end-to-end data-to-visualization workflows.
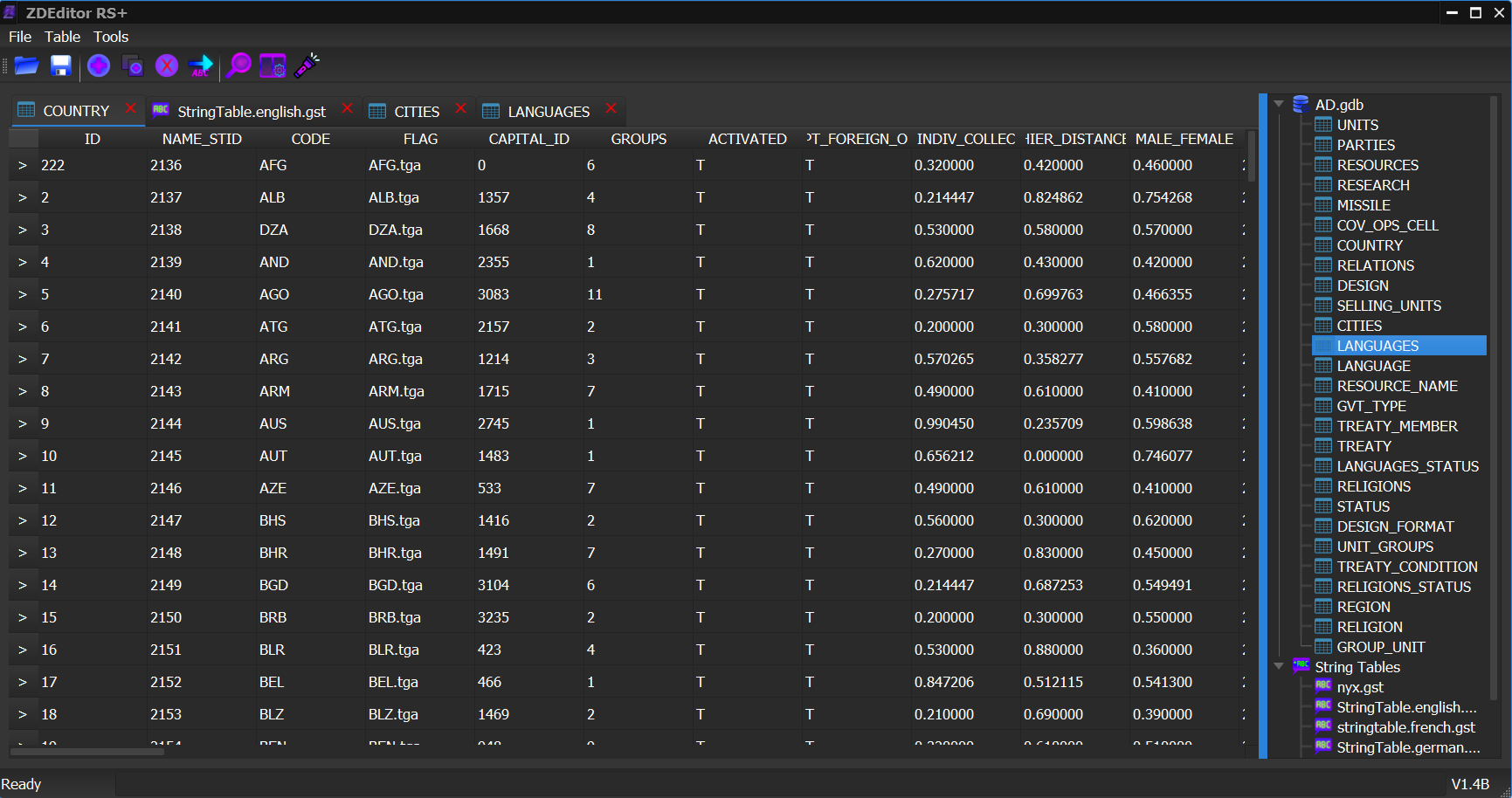
Modern C++ rewrite of the SuperPower 2 database modding tool. Became the community standard for modding with a maintainable long-term codebase.
Intensive C++, Qt, and WinAPI work through community tooling built strong systems instincts, fast iteration habits, and direct feedback loops with real users.
Early software years moved from Visual Basic and C# roots into C++-first development, setting up the systems depth that later supported ML and research work.